
网站robots协议的使用
发布于:2015-04-086200 人看过本文归属目录:SEO基础入门学习,新手如何学习SEO
1.robots协议是什么?
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol)。
网站中的robots.txt是指网站和搜索引擎之间的协议。
网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
robots协议的作用是减少网站无效页面的收录,集中页面权重。
robots.txt的生效期时间比较长,一般会在一个月左右。
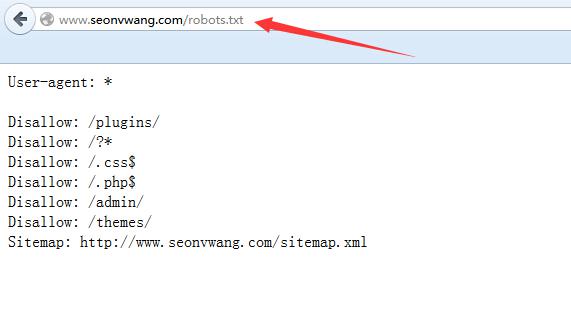
查看robots.txt的方法:
是在路径后面直接加上robots.txt回车就可以看到了。
2.robots.txt协议语法解析
User-agent: *
开头字母必须是大写的,后面加英文形式下的冒号,然后后面是空格。
*表示通配符号。这里指通配所有的搜索引擎。
Disallow: / 表示禁止搜索引擎爬取所有页面,/表示目录。
Disallow: 表示不禁止
Disallow: /admin/禁止爬取admin后台目录。
Disallow: /admin 禁止抓取包含admin的路径 后面不带/表示只要路径中包含admin蜘蛛就不会抓取。
Allow: 表示允许
Allow: /admin/s3.html 允许抓取admin目录下的s3.html 这个文件。
Disallow: /.css$ 表示以.css结尾的文件都不允许抓取,带上$表示特定的文件。
3.robots.txt协议写法注意点
注意:
所有的语法必须空格/开头,所有正规的搜索引擎在抓取网站URL的时候会第一时间抓取robots.txt,如果没有robots.txt文件,蜘蛛会默认网站允许抓取所有信息。
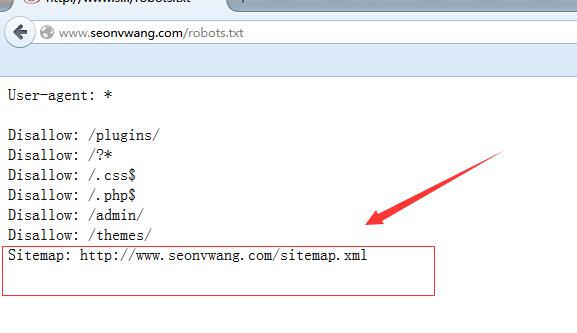
网站地图放在robots.txt文件里。
所以把网站地图放在robots.txt文件夹里可以让蜘蛛更快速的抓取网站路径。 把做好的XML地图写在robots.txt文件里上传根目录就好。
女王语录:
单纯的文字笔记是不是不好理解呢?结合教程学习更容易理解哦《网站robots协议的使用教程》
基础入门本文标签

每晚20.00课堂直播分享:快速提升网站排名SEO实战操作技能
快来跟着贝贝一起学习吧!马上加QQ领取最新SEO顶尖教程
- seo教程空调木托企业网站排名<<上一篇
- 网站robots协议的使用教程<<下一篇


